DEEP LEARNING CRASH COURSE CON KERAS Y TENSORFLOW
Este notebook ha sido creado con el objetivo de dar una primera toma de contacto con el mundo del Deep Learning, aportando un poco de historia y motivación de las redes neuronales, intentando otorgar un suficiente conocimiento del perceptrón de un capa y multicapa, y describiendo brevemente arquitecturas más complejas.
QUE ENCONTRARÁS EN ESTE NOTEBOOK
- ¿Es posible que una máquina pueda imitar el comportamiento del cerebro humano?
- Neuronas biológicas
- Redes neuronales artificiales
- MNIST
- Gradient Descent
- Retropropagación
- HANDS-ON DEEP LEARNING
- Redes Neuronales Convolucionales
- Modelos pre-entrenados
- Instalación de TensorFlow
- A hombros de gigante
¿Es posible que una máquina pueda imitar el comportamiento del cerebro humano?
 Seguramente cuando pensamos en máquinas comportándose de manera inteligente no podemos evitar pensar en Inteligencia Artificial(IA), y nuestra intuición es correcta ya que la IA es un campo que busca que las computadoras se comporten de manera inteligente. Con computadores compartándose de manera inteligente no nos referimos a robots del futuro que han venido a destruir la humanidad, nos referimos a una realidad que lleva muchas décadas de estudio. Desde cosas tan cotidianas como vuestro filtro de spam, Siri, el traductor de Google o recomendaciones de videos en YouTube hasta coches autónomos son ejemplos de máquinas comportándose de manera inteligente. ¿Por qué? Porque dichas máquina contienen una serie de algoritmos que les hacen comportarse de esa manera, queremos decir que cuando te llega un email y se clasifica en spam, y no en tu bandeja de entrada, no es porque haya una persona que mira cada uno de tus emails y los clasifica, si no que hay un algoritmo que a través de unos datos de entrada, como el emisor del correo, las palabras que hay en el correo, etc… clasifica entre spam y no spam. Es evidente que si el correo contiene palabras como ‘descuento’, ‘compra’, ‘oferta’ es probable que estemos hablando de spam. Visto esto podemos afirmar que tu filtro de spam esta exhibiendo un comportamiento inteligente.
Seguramente cuando pensamos en máquinas comportándose de manera inteligente no podemos evitar pensar en Inteligencia Artificial(IA), y nuestra intuición es correcta ya que la IA es un campo que busca que las computadoras se comporten de manera inteligente. Con computadores compartándose de manera inteligente no nos referimos a robots del futuro que han venido a destruir la humanidad, nos referimos a una realidad que lleva muchas décadas de estudio. Desde cosas tan cotidianas como vuestro filtro de spam, Siri, el traductor de Google o recomendaciones de videos en YouTube hasta coches autónomos son ejemplos de máquinas comportándose de manera inteligente. ¿Por qué? Porque dichas máquina contienen una serie de algoritmos que les hacen comportarse de esa manera, queremos decir que cuando te llega un email y se clasifica en spam, y no en tu bandeja de entrada, no es porque haya una persona que mira cada uno de tus emails y los clasifica, si no que hay un algoritmo que a través de unos datos de entrada, como el emisor del correo, las palabras que hay en el correo, etc… clasifica entre spam y no spam. Es evidente que si el correo contiene palabras como ‘descuento’, ‘compra’, ‘oferta’ es probable que estemos hablando de spam. Visto esto podemos afirmar que tu filtro de spam esta exhibiendo un comportamiento inteligente.
Uno de los subcampos de la IA es el Machine Learning el cual busca darle a un programa las herramientas necesarias para que pueda aprender. Basicamente, cuando hablamos de ML estamos hablando de crear un modelo que intente predecir la realidad. ¿Cómo llegamos a ese modelo?. Se suele decir que los datos son el oro del siglo XXI, y efectivamente utilizamos datos para ‘entrenar’ nuestro modelo. Cuando nos referimos a entrenar estamos haciendo alusión al proceso a partir del cual un computadora aprende a partir de datos como comportarse cuando se encuentre en nuevas situaciones con nuevos datos.
En el caso de un filtrador de spam, los datos con los que entrenamos nuestro modelo son los ya comentados remitente, palabras…
Algoritmos de Machine Learning hay muchos, en este notebook vamos a ver como resuelven este tipo de problemas los algoritmos de Deep Learning.
Neuronas biológicas
El ser humano ha basado alguna de sus invenciones en la naturaleza, ¿Por qué no hacerlo para conseguir un comportamiento inteligente? Cuando pensamos en el cerebro humano seguramente se nos venga a la cabeza las decenas de miles de millones de neuronas que este tiene. Estas neuronas, como vemos en la imagen inferior, cuenta con cuerpo celular, dentritas y una larga extensión llamada axón. Estas se comunican a través de señales elécticas que se producen desde el axón de unas, y son recibidas por las dendritas de otras.
 Si estuviesemos interesados en conseguir un comportamiento inteligente mirar al cerebro humano como inspiración parece una buena idea.
Si estuviesemos interesados en conseguir un comportamiento inteligente mirar al cerebro humano como inspiración parece una buena idea.
Redes neuronales artificiales
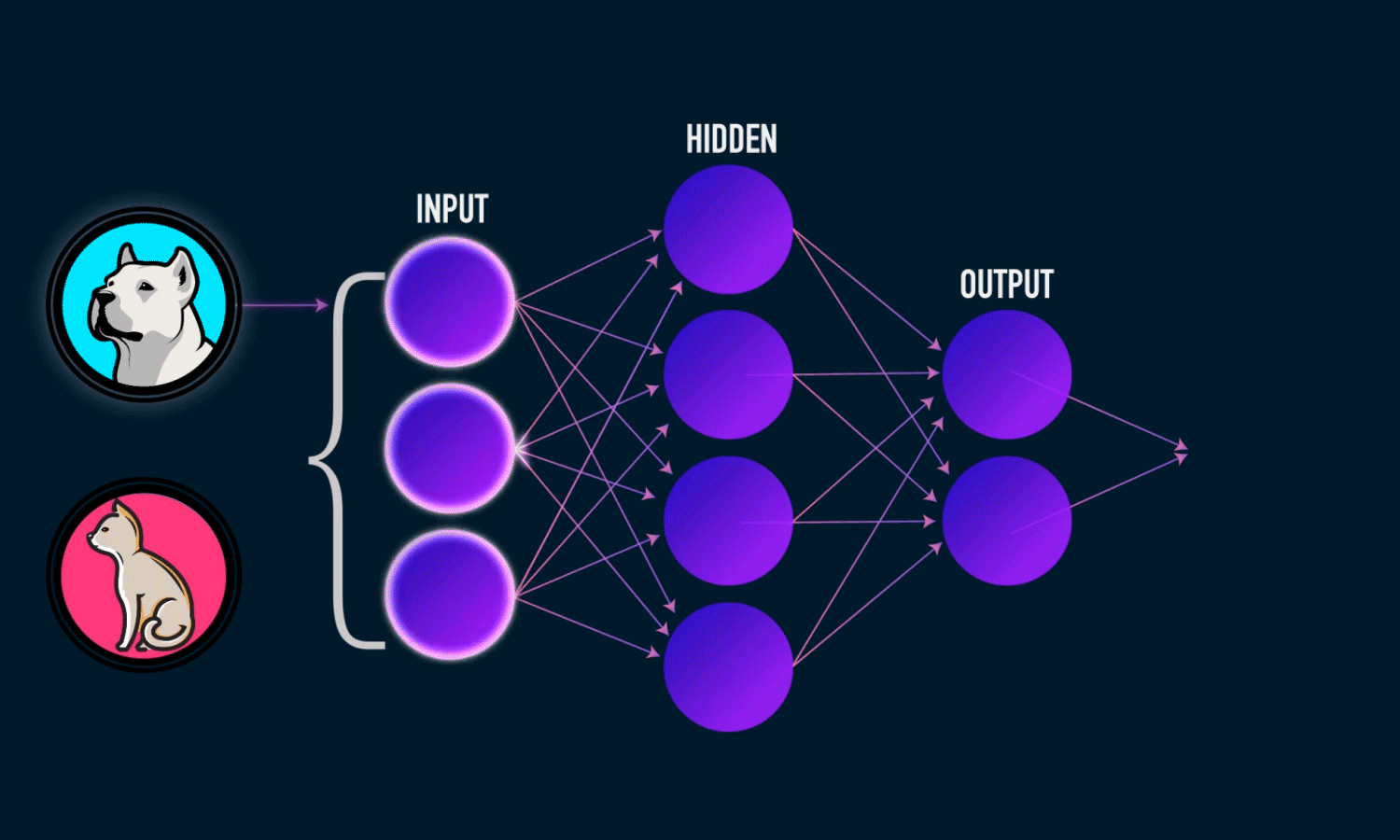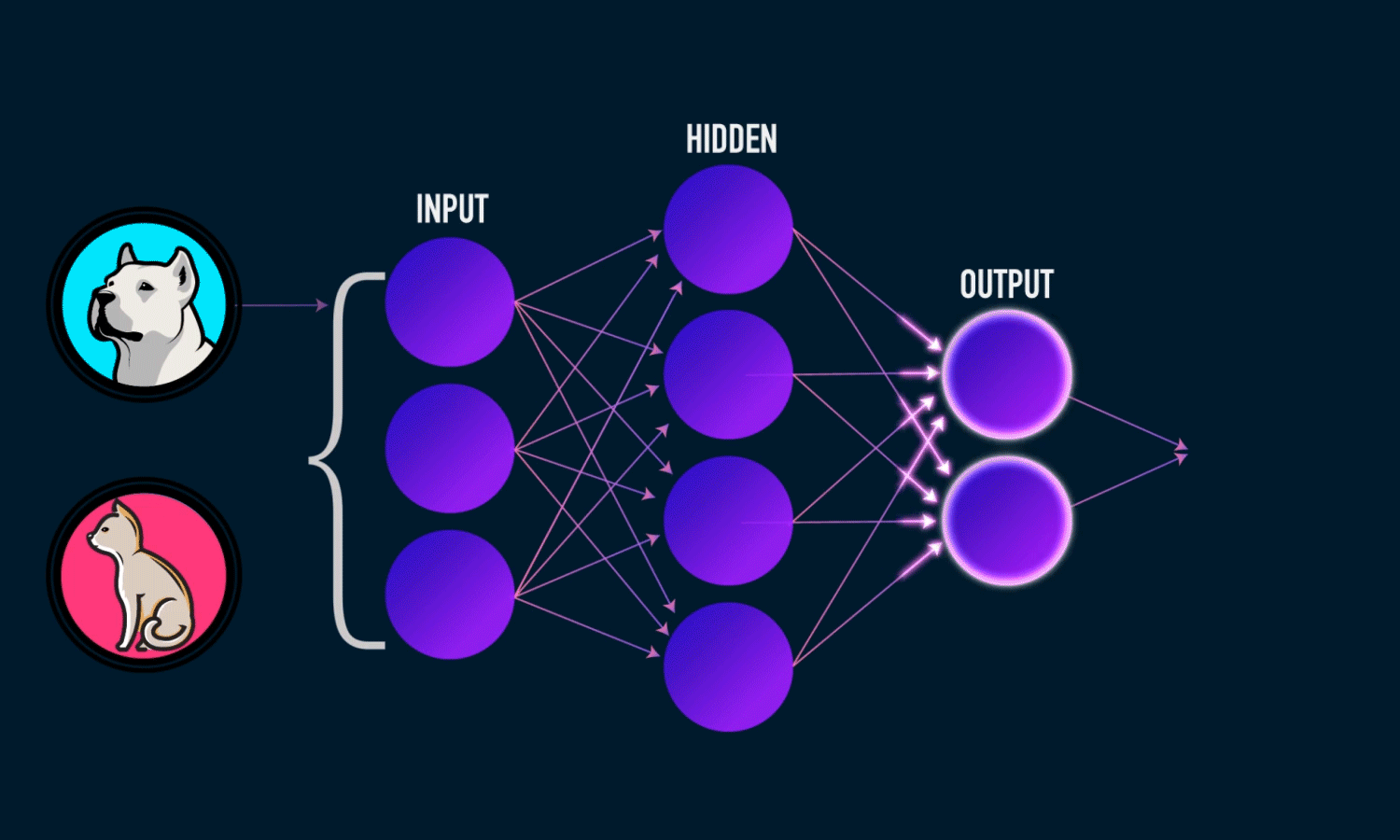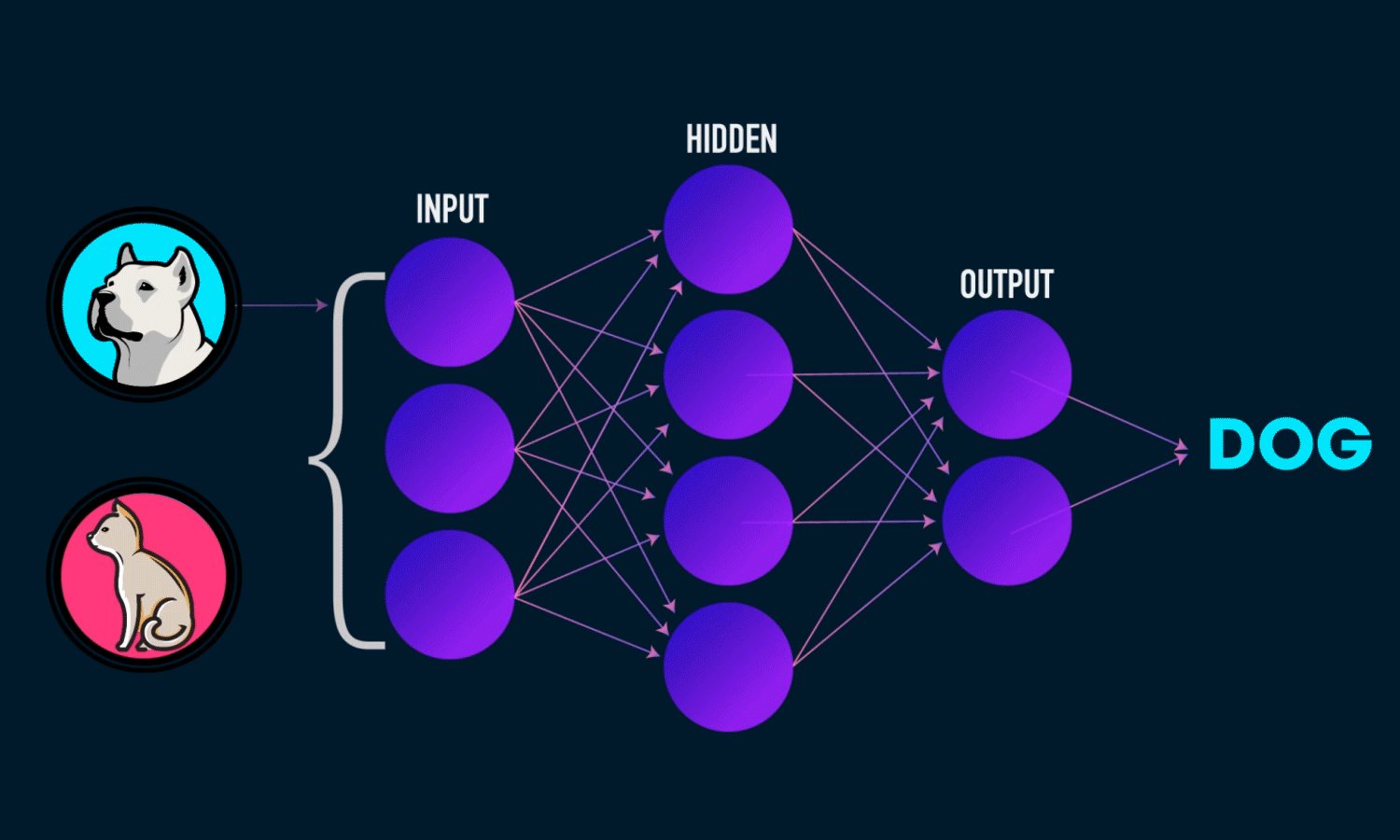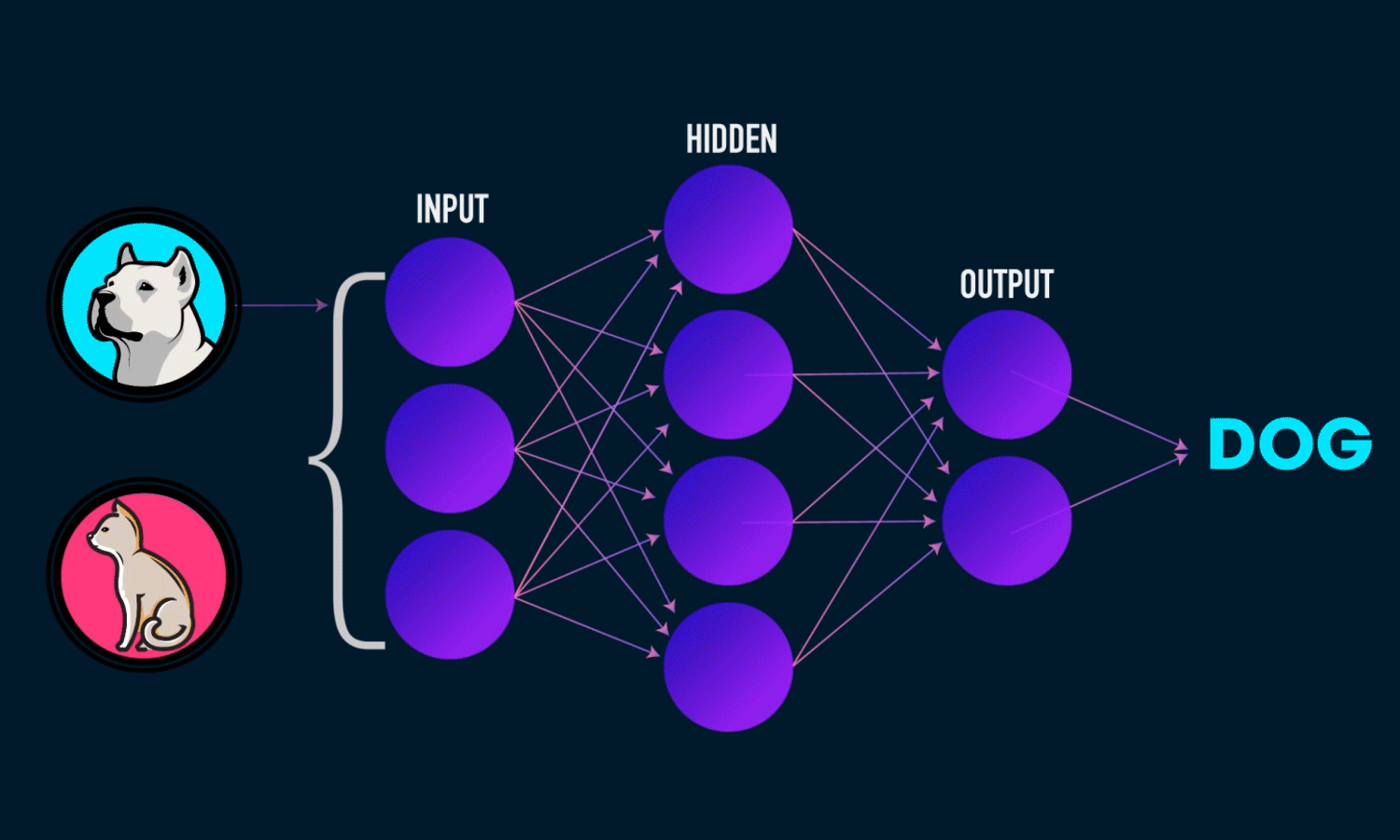
Esta neurona biológica nos lleva a hablar de su homóloga computacional, si, hablamos de neuronas artificiales. Precisamente el Deep Learning está fundamentado en el uso de redes neuronales artificales. Pero, ¿Cómo funcionan? Imaginemos que queremos contruir un clasificador de animales a partir de una foto, es decir le introducimos como entrada un foto de un animal y nos devuelve como salida el nombre de dicho animal. Para ello podemos utilizar una red neuronal. De una manera muy simple podemos definir una red neuronal como un modelo que recibe una entrada, en este caso una imagen, y nos devuelve una salida, es decir, nos dice si la imagen contenía un perro o un gato.
def visualize_input(img, ax):
ax.imshow(img, cmap='gray')
width, height = img.shape
thresh = img.max()/2.5
for x in range(width):
for y in range(height):
ax.annotate(str(round(img[x][y],2)), xy=(y,x),
horizontalalignment='center',
verticalalignment='center',
color='white' if img[x][y]<thresh else 'black')Primero de todo,vamos a ver qué es realmente una red neuronal. Una red neuronal artificial básica se compone de tres capas, una de entrada, una oculta y una de salida, veremos, que puede haber múltiples capas ocultas, tantas como de compleja queremos que sea nuestra red, una capa es un conjunto de neuronas cuyas entradas provienen de una capa anterior (o de los datos de entrada en el caso de la primera capa) y cuyas salidas son la entrada de una capa posterior. En la capa de entrada las neuronas reciben los datos que el usuario le proporciona, ya sean imágenes etc… las capas ocultas son las que se encargan de realizar todo el aprendizaje reduciendo en cada iteración su error a la hora de decidir, por ejemplo, si la foto se trata de un perro o un gato. Por último, la capa de salida consta de el “output”, es decir, la que nos va a indicar de que se trata la imagen, en el caso de que los datos de entrada sean una imagen
Ahora, vamos a explicar brevemente el funcionamiento de una red neuronal, para ello vamos a explicar como funciona una sola neurona de la red. Una neurona recibe está conectada a todas las neuronas de las capas anterior y posterior, y ésta puede activarse y por consecuencia trasladar la información a la siguiente capa, o no activarse. Esa decisión la “toma” la llamada función de activación, existen múltiples funciones de activación pero antes de ver qué es lo que hace esta función vamos a ver lo que contiene esta función que provoca que la neurona se active, o por el contrario, no lo haga. Bien, cada neurona almacena un valor generalmente entre 0 y 1, vamos a denotar este valor como \(a_{j}\) dónde \(j\) identifica la posición de la neurona en la capa actual, por otra parte, cada conexión guarda un peso \(\omega\), ésta neurona de la que estamos hablando sería la neurona \(j\) y cada neurona de la capa anterior asociada a ésta le traslada un producto \((a_{j}\omega_{jk})\), donde \(k\) marca la posición de la neurona de la capa anterior, por otro lado, cada neurona almacena un valor BIAS o sesgo \(b\) el cuál va a ayudar a que esa neurona se active antes que otras. Sabiendo ésto, el sumatorio \((\displaystyle\sum_{j=1}^n{a}^{(L)}_{j}\omega_{jk}^{(L)})+b\), donde \(n\) es el numero de neuronas en la capa \(L\), sería el valor con el que la función de activación debe decidir si activar a la neurona o no; muy simplificadamente, si el resultado del sumatorio supera un determinado valor, la función activa la neurona.

MNIST
Vamos a ver más a fondo como funciona una red neuronal, para ello vamos a usar la API de TensorFlow Keras, una API es un programa con nos permite interactuar con otro simplificando su uso, esto quiere que decir que Keras nos permite trabajar con TensorFlow de una manera más sencilla. Cargamos el conjunto de datos MNIST, este conjunto cuanta con 70000 imagenes de números manuscritos, para cada imagen tenemos una matriz donde cada elemento es un pixel de la imagen.

from tensorflow import keras
(imagenes_entrenamiento, etiquetas_entrenamiento), (imagenes_test, etiquetas_test) = keras.datasets.mnist.load_data()Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11493376/11490434 [==============================] - 0s 0us/stepEl método “load_data” nos permite cargar los datos de la base. La asignación de esas dos tuplas que vemos arriba puede resultar confusa, vamos a explicarlo brevemente.
keras.datasets.mnist.load_data() ((array([[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
...,
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]], dtype=uint8),
array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)),
(array([[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
...,
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]],
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]], dtype=uint8),
array([7, 2, 1, ..., 4, 5, 6], dtype=uint8)))Estos datos conforman dos tuplas, cada una de ellas contienendo un array de tres dimensiones, donde cada imagen está almacenada en una matriz; y un vector, donde cada elemento es el número que corresponde a dicha matriz.
print(f'Numero que representa la matriz matriz: {etiquetas_entrenamiento[1]}')
print(f'Cada elemento corresponde a un pixel: \n {imagenes_entrenamiento[1]}') Número que representa la matriz matriz: 0
Cada elemento corresponde a un pixel:
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 51 159 253
159 50 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 48 238 252 252
252 237 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 54 227 253 252 239
233 252 57 6 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 10 60 224 252 253 252 202
84 252 253 122 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 163 252 252 252 253 252 252
96 189 253 167 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 51 238 253 253 190 114 253 228
47 79 255 168 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 48 238 252 252 179 12 75 121 21
0 0 253 243 50 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 38 165 253 233 208 84 0 0 0 0
0 0 253 252 165 0 0 0 0 0]
[ 0 0 0 0 0 0 0 7 178 252 240 71 19 28 0 0 0 0
0 0 253 252 195 0 0 0 0 0]
[ 0 0 0 0 0 0 0 57 252 252 63 0 0 0 0 0 0 0
0 0 253 252 195 0 0 0 0 0]
[ 0 0 0 0 0 0 0 198 253 190 0 0 0 0 0 0 0 0
0 0 255 253 196 0 0 0 0 0]
[ 0 0 0 0 0 0 76 246 252 112 0 0 0 0 0 0 0 0
0 0 253 252 148 0 0 0 0 0]
[ 0 0 0 0 0 0 85 252 230 25 0 0 0 0 0 0 0 0
7 135 253 186 12 0 0 0 0 0]
[ 0 0 0 0 0 0 85 252 223 0 0 0 0 0 0 0 0 7
131 252 225 71 0 0 0 0 0 0]
[ 0 0 0 0 0 0 85 252 145 0 0 0 0 0 0 0 48 165
252 173 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 86 253 225 0 0 0 0 0 0 114 238 253
162 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 85 252 249 146 48 29 85 178 225 253 223 167
56 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 85 252 252 252 229 215 252 252 252 196 130 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 28 199 252 252 253 252 252 233 145 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 25 128 252 253 252 141 37 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]]Cada imagen de MNIST tienen unas dimensiones de 28x28 pixeles, por lo que para cada imagen contamos con una matriz de 28 filas y 28 columnas. Lo que visulizamos debajo es una imagen que corresponde a un 0 y cada píxel viene identificado con su escala de gris, la cual va desde 0 hasta 255.
imagenes_entrenamiento[0].shape (28, 28)import matplotlib.pyplot as plt
fig = plt.figure(figsize = (12,12))
ax = fig.add_subplot(111)
ax.set_yticklabels([])
ax.set_xticklabels([])
plt.axis('off')
visualize_input(imagenes_entrenamiento[1], ax)
La primera tupla, (imagenes_entrenamiento, etiquetas_entrenamiento), se reservará para entrenar a nuestra red neuronal, y la segunda, (imagenes_test, etiquetas_test), para evaluar su porcentaje de acierto sin ser entrenada en esta evaluación. Evidentemente, no debemos poner a prueba a la red con las mismos datos de entrenamiento; de otra forma, tratará con imágenes que ya ha estudiado.
Antes de explicar la creación de este cerebro electrónico, explicaremos dos conceptos esenciales que intervienen en la modificación de la red neuronal.
Gradient Descent
Gradient Descent (o Descenso de Gradiente) es un algoritmo que permite hallar el mínimo de una función, que en nuestro caso será la función de coste o de pérdida, que depende de los parámetros de la red y tiene como imagen el error para dichos parámetros. Un ejemplo de función de coste podría ser \(\frac{1}{n}\displaystyle\sum_{i=1}^{n} (y_i-\hat{y_i})^{2}\) donde \(y\) sería el valor real e \(\hat{y}\) el valor predicho. El sumatorio recorre todos los ejemplos en nuestro conjunto de entrenamiento. Imaginemos que nuestra predicción viene dada por una recta, es decir \(\hat{y} = \theta_1 x + \theta_0\), donde \(\theta_1\) denota la pendiente y \(\theta_0\) el término independiente. Podemos realizar la siguiente sustitución \(\frac{1}{n}\displaystyle\sum_{i=1}^{n} (y_i- \theta_1 x_i - \theta_0)^{2}\). Nuestro objetivo es encontrar los parámetros de \(\theta_0\) y \(\theta_1\) que minimizan esta función de coste. Gradient Descent actualiza los parámetros en cada iteración, restándoles el gradiente de la función, dado que sabemos que \(\nabla f(\theta_0, \theta_1)\) es la dirección de ascenso más pronunciado, de lo que sigue inmediatamente que \(-\nabla f(\theta_0, \theta_1)\) es la de descenso más pronunciado, por lo que ir en la dirección de -\(\nabla f(\theta_0, \theta_1)\) nos garantiza que en cada iteración nos estaremos acercando al mínimo (aunque, por razones que no explicaremos, podría darse el caso de que GD falle en la tarea de dar con el mínimo).
Retropropagación
La distribución correcta de pesos entre neuronas es un problema crucial. Una red neuronal es incapaz de determinar el resultado correcto si estos pesos son adjudicados aleatoriamente. Precisamente existe una elegante solución para lidiar con ellos, que viene dada por el algoritmo de retropropagación (o backpropagation en inglés). Cabe mencionar que tal algoritmo tiene una base matemática que, aunque interesante y desde luego esencial, dejaremos de lado para así tomar un enfoque intuitivo.
La idea de la retropropagación consiste en ajustar los parámetros de la red neuronal de acuerdo con la minimización de la función de coste o pérdida, de la que se puede encargar un optimizador como Descenso de Gradiente. Tal función de pérdida podría ser, por ejemplo, la función de error cuadrático. Como ya se ha mencionado, Retropropagación y Descenso de Gradiente trabajan conjuntamente, puesto que Backpropagation proporcionará a GD el gradiente.
Si nos fijamos en la útlima capa (la salida), observaremos que las activaciones de las neuronas no concuerdan con las activaciones debidas. Centrémonos en una neurona específica cuyo valor de activación, \(a^{(L)}_j\), correspondiente a la neurona \(j\)-ésima de la capa \(L\), queremos incrementar, y que viene asociado a un peso \(\omega_{jk}^{(L)}\), el asociado a las neuronas \(j\)-ésima de la capa \(L\) y \(k\)-ésima de la capa \(L-1\). Para llevar a cabo esta tarea, consideraremos tres métodos:
- Cambio del sesgo (o bias, \(b\)): aunque trivial, es útil hacer uso de \(b\) para incrementar o decrementar \(a^{(L)}_j\).
- Incremento del peso: es evidente que un mayor peso implicará, de nuevo, un incremento de activación. Además, es importante notar que éste se realizará en proporción con \(a_j^{(L)}\), puesto que interesa aumentar más los pesos que estén asociados a \(a_j^{(L)}\) grandes, para obtener en definitiva un producto \(a_j^{(L)}\cdot\omega_{jk}^{(L)}\) grande.
- Modificación de activación: por supuesto, también querremos modificaciones de \(a_k^{(L-1)}\), para influir en el valor de \(a_j^{(L)}\). En este caso, interesa que cada activación aumente o disminuya en función de \(\omega_{jk}^{(L)}>0\) o \(\omega_{jk}^{(L)}<0\), respectivamente, manteniendo siempre un cambio de \(a_k^{(L-1)}\) en proporción con su \(\omega_{jk}^{(L)}\) asociado.
Por supuesto, no podemos simplemente transformar \(a_k^{(L-1)}\), como es el caso del último método, pero sí podemos cambiar los pesos de la capa anterior. De esta forma, repitiendo el proceso para cada capa, se irán modificando los pesos, activaciones y sesgos, hasta retornar de nuevo a la primera. Por supuesto, semejante desarrollo habrá de ser aplicado a cada neurona, completando el transcurso del algoritmo, que se aplicará a cada ejemplo de entrenamiento \(X_i\).
Finalmente, no hay que olvidar que cada ejemplo de entrenamiento producirá cambios específicos para que la red pueda reconocer, específicamente, cada uno de ellos. Por ello, es esencial tener en cuenta todas las modificaciones “propuestas” por cada $X_i$ (si no, la red neuronal tenderá a reconocer todos los datos como el mismo). Esto se puede lograr fácilmente si se computa la media del peso de cada neurona.
HANDS-ON DEEP LEARNING
Ahora estamos listos para la apasionante tarea de creación de la red neuronal.
imagenes_entrenamiento = imagenes_entrenamiento/255.0
imagenes_test = imagenes_test/255.0red_neuronal = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(100, activation="sigmoid"),
keras.layers.Dense(10, activation="softmax")
])Sequential$ es un método que permite crear $redneuronal$ mediante la definición de cada capa. $Flatten$ se encarga de “desenrollar” la matriz, cuyo tamaño indicamos en el parámetro “input_shape”, esto es, tomar sus elementos e insertarlos en un vector (por ello mismo $Flatten$ define la primera capa) y $Dense$ crea capas según el número de neuronas y función de activación requeridos.
red_neuronal.compile(loss='sparse_categorical_crossentropy',
optimizer=keras.optimizers.SGD(lr=0.1),
metrics=['accuracy'])Para terminar de configurar el modelo, habemos de especificar una función de pérdida, otra de optimización (en este caso, Descenso de Gradiente Estocástico) y un tipo de información (que la red no tendrá en cuenta, pero al humano le resultará conveniente), como puede ser el ratio de salidas acertadas y totales, que viene indicado por ‘accuracy’ o precisión en español.
early_stopping = keras.callbacks.EarlyStopping()
red_neuronal.fit(imagenes_entrenamiento, etiquetas_entrenamiento, epochs=10, validation_split=0.05, callbacks=[early_stopping]) Train on 57000 samples, validate on 3000 samples
Epoch 1/10
57000/57000 [==============================] - 4s 62us/sample - loss: 0.5643 - accuracy: 0.8542 - val_loss: 0.2551 - val_accuracy: 0.9310
Epoch 2/10
57000/57000 [==============================] - 3s 54us/sample - loss: 0.3042 - accuracy: 0.9117 - val_loss: 0.2068 - val_accuracy: 0.9463
Epoch 3/10
57000/57000 [==============================] - 3s 54us/sample - loss: 0.2603 - accuracy: 0.9249 - val_loss: 0.1804 - val_accuracy: 0.9517
Epoch 4/10
57000/57000 [==============================] - 3s 54us/sample - loss: 0.2296 - accuracy: 0.9337 - val_loss: 0.1621 - val_accuracy: 0.9577
Epoch 5/10
57000/57000 [==============================] - 3s 55us/sample - loss: 0.2055 - accuracy: 0.9410 - val_loss: 0.1487 - val_accuracy: 0.9640
Epoch 6/10
57000/57000 [==============================] - 3s 54us/sample - loss: 0.1857 - accuracy: 0.9466 - val_loss: 0.1426 - val_accuracy: 0.9650
Epoch 7/10
57000/57000 [==============================] - 3s 54us/sample - loss: 0.1688 - accuracy: 0.9509 - val_loss: 0.1244 - val_accuracy: 0.9697
Epoch 8/10
57000/57000 [==============================] - 3s 56us/sample - loss: 0.1549 - accuracy: 0.9556 - val_loss: 0.1180 - val_accuracy: 0.9727
Epoch 9/10
57000/57000 [==============================] - 3s 55us/sample - loss: 0.1429 - accuracy: 0.9587 - val_loss: 0.1141 - val_accuracy: 0.9730
Epoch 10/10
57000/57000 [==============================] - 3s 55us/sample - loss: 0.1325 - accuracy: 0.9618 - val_loss: 0.1064 - val_accuracy: 0.9737
<tensorflow.python.keras.callbacks.History at 0x7fa820ebe908>Ahora que la red ha sido creada, debemos entrenarla. Este proceso lo indicamos mediante el método $fit$, en el que especificamos los datos de entrenamiento y el número de iteraciones o epochs sobre dichos datos. Adicionalmente, se han incluido “validation_split”, que excluye de la fase de entrenamiento un 5% de los datos, escogidos del final del conjunto de entrenamiento, para realizar pequeñas pruebas de la red al final de cada epoch; y “callbacks”, en el que escogemos un callback, propiamente dicho, en este caso, “early stopping”, que detendrá el entrenamiento si éste no va a mejor, en otras palabras, si la función de pérdida empieza a incrementar su valor.
En cuanto a las salidas, obsérvese que obtenemos información como la iteración actual, el tiempo en completarla y el valor de la función de pérdida y la precisión, tanto para el conjunto de entrenamiento como para el de validación (“val_loss” y “val_accuracy”).
Finalmente, ponemos a prueba nuestra red mediante los datos de test.
red_neuronal.evaluate(imagenes_test, etiquetas_test)10000/10000 [==============================] - 0s 37us/sample - loss: 0.1359 - accuracy: 0.9600 [0.13591611904501916, 0.96]Improving our model
red_neuronal_2 = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.BatchNormalization(),
keras.layers.Dense(200, activation="selu", kernel_initializer="lecun_normal"),
keras.layers.BatchNormalization(),
keras.layers.Dense(100, activation="selu", kernel_initializer="lecun_normal"),
keras.layers.BatchNormalization(),
keras.layers.Dense(10, activation="softmax")
])Tras añadir alguna capa oculta y el método $BatchNormalization$, el cuál transforma los valores de la función de activación de tal forma que la media se mantenga próxima a 0 y la desviación típica a 1, nuestra red neuronal mejorará considerablemente
red_neuronal_2.compile(loss='sparse_categorical_crossentropy',
optimizer=keras.optimizers.SGD(lr=0.05),
metrics=['accuracy'])imagenes_entrenamiento = imagenes_entrenamiento/255
red_neuronal_2.fit(imagenes_entrenamiento, etiquetas_entrenamiento, epochs=10, validation_split=0.1, callbacks=[early_stopping]) Train on 54000 samples, validate on 6000 samples
Epoch 1/10
54000/54000 [==============================] - 6s 114us/sample - loss: 0.3248 - accuracy: 0.9037 - val_loss: 0.1571 - val_accuracy: 0.9560
Epoch 2/10
54000/54000 [==============================] - 5s 101us/sample - loss: 0.1924 - accuracy: 0.9433 - val_loss: 0.1209 - val_accuracy: 0.9658
Epoch 3/10
54000/54000 [==============================] - 5s 101us/sample - loss: 0.1498 - accuracy: 0.9553 - val_loss: 0.1061 - val_accuracy: 0.9692
Epoch 4/10
54000/54000 [==============================] - 5s 100us/sample - loss: 0.1256 - accuracy: 0.9625 - val_loss: 0.0966 - val_accuracy: 0.9723
Epoch 5/10
54000/54000 [==============================] - 5s 99us/sample - loss: 0.1071 - accuracy: 0.9675 - val_loss: 0.0856 - val_accuracy: 0.9765
Epoch 6/10
54000/54000 [==============================] - 5s 100us/sample - loss: 0.0951 - accuracy: 0.9712 - val_loss: 0.0857 - val_accuracy: 0.9757
<tensorflow.python.keras.callbacks.History at 0x7fa8180d01d0>red_neuronal_2.evaluate(imagenes_test/255, etiquetas_test) 10000/10000 [==============================] - 0s 45us/sample - loss: 0.0881 - accuracy: 0.9729 [0.08812100926879793, 0.9729]Desde luego, una red digna de admiración.
Redes Neuronales Convolucionales(CNN)
La arquitectura de red neuronal que hemos visto hasta ahora funcionaba bien con MNIST, tomando en cuenta que estábamos tratando imágenes en blanco y negro, y su resolución, 28px x 28px, no era gran cosa. Esto resultaba en una capa de entrada de 784 neuronas, lo cual no era demasiado, con una hipotética segunda capa de 200 neuronas, obtendríamos casi 160000 parámetros, solo en la primera capa. Este número de neuronas, no resulta muy demandante a nivel computacional. Sin embargo, cuando pasamos a imagenes en color, y con mayor resolución, nuestra red neuronal empieza a flaquear, debido a la gran dimensionalidad de la capa de entrada.

Esta imagen tiene 1920px de ancho y 1079px de alto, a lo que habría que sumarle los 3 canales de color por cada pixel, en total, tendriamos una primera capa de entrada con más de 6 millones de neuronas, suponiendo una primera capa oculta de 200 neuronas, tendriamos mil millones de parámetros solo en la primera capa. Una Red Neuronal Convolucional soluciona esto usando capas parcialmente conectadas y parámetros(pesos) compartidos.
Desventajas de una Red Neuronal común frente a una convolucional:
- Los inputs son independientes, en el caso de una imagen, se asume que cada píxel es independiente del resto, lo cual puede no ser adecuado, si estamos trabajando con una imagen que contiene una cara, los pixeles que están alrededor del ojo, tienen cierta relación, es decir, forman un patrón que está presente en todas las caras humanas. Y esta es la suposición a la hora de formar una red neuronal convolucional. Los píxeles de la capa de entrada (el array contenedor de la imagen) que están cercanos entre ellos tienen un relación.

- Otro factor importante, es que una red neuronal común, una vez aprende a reconocer un patrón en una determinada localización, sólo puede reconocerla en dicha localización.
El bloque fundamental en una CNN es la capa convolucional, donde a la imagen de entrada se le aplican convoluciones, podemos ver debajo que las neuronas de entrada de una capa convolucional no están conectadas a todas las neuronas de la segunda, si no únicamente a ciertas neuronas en un determinado rango. Ocurre lo mismo con las neuronas de la tercera capa convolucional con respecto a la segunda.

Las convoluciones nos permiten capturar características de una imagen, aplicando filtros. Tomando como ejemplo esta imagen, vamos a explorar estos filtros.

El filtro en la siguiente imagen, es la matriz roja que vemos, en este caso nos permite resaltar las líneas verticales.
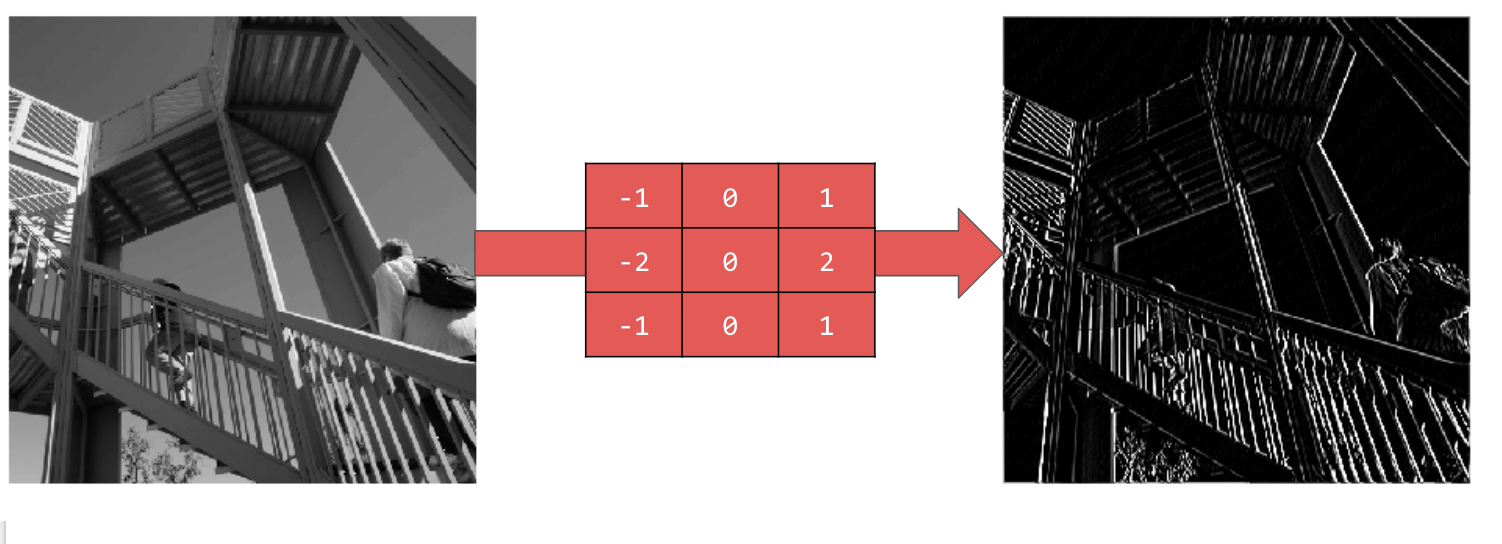
Este filtro resalta las líneas horizontales
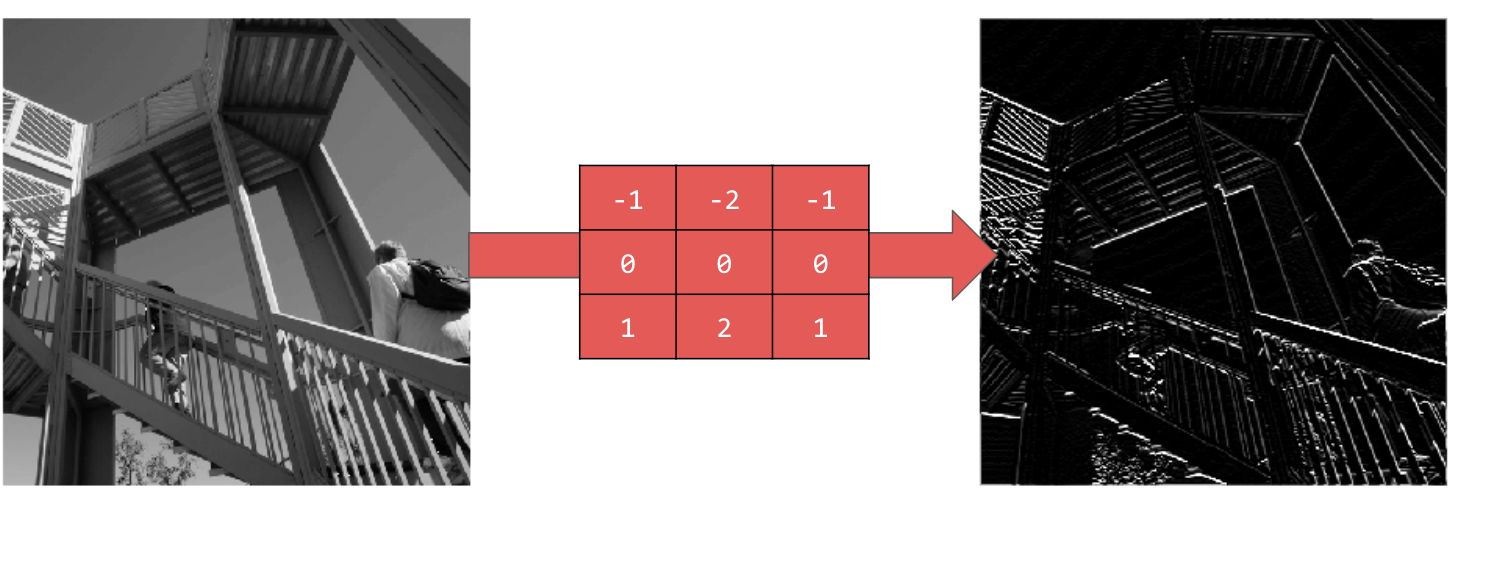
El proceso en el que aplicamos un filtro a una imagen, es la convolución. Los filtros que se aplican se pueden tratar como parámetros, por lo que pueden ser aprendidos en el proceso de entrenamiento.
El otro bloque que construye una red neuronal convolucional es la capa de pooling, como en la capa convolucional las neuronas de una capa sólo están relacionadas con algunas neuronas de la capa anterior:

La capa de pooling consiste en reducir la información sin reducir las características presentes en nuestros datos. Un ejemplo sería el aplicado en la imagen de arriba, donde cogemos el número más grande en un determinado rango.
Una vez aplicadas las operaciones de convolución y pooling pasamos nuestras neuronas a una red totalmente conectado como la que vimos con MNIST, esta sería un arquitectura de una red neuronal convolucional:

cnn = keras.models.Sequential([
keras.layers.Conv2D(64, kernel_size=3, activation='relu', input_shape= (28,28, 1)),
keras.layers.MaxPooling2D(),
keras.layers.Flatten(),
keras.layers.BatchNormalization(),
keras.layers.Dense(200, activation="selu", kernel_initializer="lecun_normal"),
keras.layers.BatchNormalization(),
keras.layers.Dense(100, activation="selu", kernel_initializer="lecun_normal"),
keras.layers.BatchNormalization(),
keras.layers.Dense(10, activation="softmax")
])cnn.compile(optimizer=keras.optimizers.SGD(lr=0.05), loss='sparse_categorical_crossentropy', metrics=['accuracy'])imagenes_test = imagenes_test.reshape(10000, 28, 28, 1)
imagenes_entrenamiento = imagenes_entrenamiento.reshape(60000, 28, 28, 1)
cnn.fit(imagenes_entrenamiento, etiquetas_entrenamiento, epochs=30, callbacks=[early_stopping]) Train on 60000 samples
Epoch 1/30
60000/60000 [==============================] - 40s 663us/sample - loss: 0.1745 - accuracy: 0.9473
Epoch 2/30
60000/60000 [==============================] - 39s 652us/sample - loss: 0.0891 - accuracy: 0.9727
Epoch 3/30
60000/60000 [==============================] - 39s 649us/sample - loss: 0.0680 - accuracy: 0.9791
Epoch 4/30
60000/60000 [==============================] - 40s 667us/sample - loss: 0.0562 - accuracy: 0.9821
Epoch 5/30
60000/60000 [==============================] - 39s 650us/sample - loss: 0.0464 - accuracy: 0.9858
Epoch 6/30
60000/60000 [==============================] - 39s 653us/sample - loss: 0.0399 - accuracy: 0.9873
Epoch 7/30
60000/60000 [==============================] - 39s 652us/sample - loss: 0.0324 - accuracy: 0.9900
Epoch 8/30
60000/60000 [==============================] - 39s 645us/sample - loss: 0.0285 - accuracy: 0.9910
Epoch 9/30
60000/60000 [==============================] - 39s 652us/sample - loss: 0.0255 - accuracy: 0.9922
Epoch 10/30
60000/60000 [==============================] - 39s 652us/sample - loss: 0.0203 - accuracy: 0.9941
Epoch 11/30
60000/60000 [==============================] - 39s 642us/sample - loss: 0.0174 - accuracy: 0.9949
Epoch 12/30
60000/60000 [==============================] - 40s 665us/sample - loss: 0.0176 - accuracy: 0.9948
Epoch 13/30
60000/60000 [==============================] - 42s 701us/sample - loss: 0.0140 - accuracy: 0.9959
Epoch 14/30
60000/60000 [==============================] - 39s 645us/sample - loss: 0.0138 - accuracy: 0.9960
Epoch 15/30
60000/60000 [==============================] - 39s 649us/sample - loss: 0.0119 - accuracy: 0.9965
Epoch 16/30
60000/60000 [==============================] - 39s 651us/sample - loss: 0.0104 - accuracy: 0.9969
Epoch 17/30
60000/60000 [==============================] - 39s 646us/sample - loss: 0.0094 - accuracy: 0.9973
Epoch 18/30
60000/60000 [==============================] - 39s 649us/sample - loss: 0.0079 - accuracy: 0.9980
Epoch 19/30
21600/60000 [=========>....................] - ETA: 24s - loss: 0.0076 - accuracy: 0.9979cnn.evaluate(imagenes_test, etiquetas_test) 10000/10000 [==============================] - 2s 174us/sample - loss: 516.3232 - accuracy: 0.4601 [516.3232142578125, 0.4601]Modelos pre-entrenados
TensorFlow nos da la oportunidad de descargar modelos ya entrenados, en el modulo keras.applications, en este caso estamos seleccionando como modelo ResNet-50, el cual ha sido entrenado en el conjunto de datos ImageNet, este dataset contiene 14 millones de imagenes etiquetadas, las cuales ocupan 14GB!! MNIST tiene 10 clases, los numeros del 0 al 9, ImageNet cuenta con 1000 CLASES!!

neural_network_on_steroids = keras.applications.resnet50.ResNet50(weights="imagenet") Downloading data from https://github.com/keras-team/keras-applications/releases/download/resnet/resnet50_weights_tf_dim_ordering_tf_kernels.h5
102973440/102967424 [==============================] - 3s 0us/stepEsta es la arquitectura de ResNet-50
neural_network_on_steroids.summary() Model: "resnet50"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 224, 224, 3) 0
__________________________________________________________________________________________________
conv1_pad (ZeroPadding2D) (None, 230, 230, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv1_conv (Conv2D) (None, 112, 112, 64) 9472 conv1_pad[0][0]
__________________________________________________________________________________________________
conv1_bn (BatchNormalization) (None, 112, 112, 64) 256 conv1_conv[0][0]
__________________________________________________________________________________________________
conv1_relu (Activation) (None, 112, 112, 64) 0 conv1_bn[0][0]
__________________________________________________________________________________________________
pool1_pad (ZeroPadding2D) (None, 114, 114, 64) 0 conv1_relu[0][0]
__________________________________________________________________________________________________
pool1_pool (MaxPooling2D) (None, 56, 56, 64) 0 pool1_pad[0][0]
__________________________________________________________________________________________________
conv2_block1_1_conv (Conv2D) (None, 56, 56, 64) 4160 pool1_pool[0][0]
__________________________________________________________________________________________________
conv2_block1_1_bn (BatchNormali (None, 56, 56, 64) 256 conv2_block1_1_conv[0][0]
__________________________________________________________________________________________________
conv2_block1_1_relu (Activation (None, 56, 56, 64) 0 conv2_block1_1_bn[0][0]
__________________________________________________________________________________________________
conv2_block1_2_conv (Conv2D) (None, 56, 56, 64) 36928 conv2_block1_1_relu[0][0]
__________________________________________________________________________________________________
conv2_block1_2_bn (BatchNormali (None, 56, 56, 64) 256 conv2_block1_2_conv[0][0]
__________________________________________________________________________________________________
conv2_block1_2_relu (Activation (None, 56, 56, 64) 0 conv2_block1_2_bn[0][0]
__________________________________________________________________________________________________
conv2_block1_0_conv (Conv2D) (None, 56, 56, 256) 16640 pool1_pool[0][0]
__________________________________________________________________________________________________
conv2_block1_3_conv (Conv2D) (None, 56, 56, 256) 16640 conv2_block1_2_relu[0][0]
__________________________________________________________________________________________________
conv2_block1_0_bn (BatchNormali (None, 56, 56, 256) 1024 conv2_block1_0_conv[0][0]
__________________________________________________________________________________________________
conv2_block1_3_bn (BatchNormali (None, 56, 56, 256) 1024 conv2_block1_3_conv[0][0]
__________________________________________________________________________________________________
conv2_block1_add (Add) (None, 56, 56, 256) 0 conv2_block1_0_bn[0][0]
conv2_block1_3_bn[0][0]
__________________________________________________________________________________________________
conv2_block1_out (Activation) (None, 56, 56, 256) 0 conv2_block1_add[0][0]
__________________________________________________________________________________________________
conv2_block2_1_conv (Conv2D) (None, 56, 56, 64) 16448 conv2_block1_out[0][0]
__________________________________________________________________________________________________
conv2_block2_1_bn (BatchNormali (None, 56, 56, 64) 256 conv2_block2_1_conv[0][0]
__________________________________________________________________________________________________
conv2_block2_1_relu (Activation (None, 56, 56, 64) 0 conv2_block2_1_bn[0][0]
__________________________________________________________________________________________________
conv2_block2_2_conv (Conv2D) (None, 56, 56, 64) 36928 conv2_block2_1_relu[0][0]
__________________________________________________________________________________________________
conv2_block2_2_bn (BatchNormali (None, 56, 56, 64) 256 conv2_block2_2_conv[0][0]
__________________________________________________________________________________________________
conv2_block2_2_relu (Activation (None, 56, 56, 64) 0 conv2_block2_2_bn[0][0]
__________________________________________________________________________________________________
conv2_block2_3_conv (Conv2D) (None, 56, 56, 256) 16640 conv2_block2_2_relu[0][0]
__________________________________________________________________________________________________
conv2_block2_3_bn (BatchNormali (None, 56, 56, 256) 1024 conv2_block2_3_conv[0][0]
__________________________________________________________________________________________________
conv2_block2_add (Add) (None, 56, 56, 256) 0 conv2_block1_out[0][0]
conv2_block2_3_bn[0][0]
__________________________________________________________________________________________________
conv2_block2_out (Activation) (None, 56, 56, 256) 0 conv2_block2_add[0][0]
__________________________________________________________________________________________________
conv2_block3_1_conv (Conv2D) (None, 56, 56, 64) 16448 conv2_block2_out[0][0]
__________________________________________________________________________________________________
conv2_block3_1_bn (BatchNormali (None, 56, 56, 64) 256 conv2_block3_1_conv[0][0]
__________________________________________________________________________________________________
conv2_block3_1_relu (Activation (None, 56, 56, 64) 0 conv2_block3_1_bn[0][0]
__________________________________________________________________________________________________
conv2_block3_2_conv (Conv2D) (None, 56, 56, 64) 36928 conv2_block3_1_relu[0][0]
__________________________________________________________________________________________________
conv2_block3_2_bn (BatchNormali (None, 56, 56, 64) 256 conv2_block3_2_conv[0][0]
__________________________________________________________________________________________________
conv2_block3_2_relu (Activation (None, 56, 56, 64) 0 conv2_block3_2_bn[0][0]
__________________________________________________________________________________________________
conv2_block3_3_conv (Conv2D) (None, 56, 56, 256) 16640 conv2_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv2_block3_3_bn (BatchNormali (None, 56, 56, 256) 1024 conv2_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv2_block3_add (Add) (None, 56, 56, 256) 0 conv2_block2_out[0][0]
conv2_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv2_block3_out (Activation) (None, 56, 56, 256) 0 conv2_block3_add[0][0]
__________________________________________________________________________________________________
conv3_block1_1_conv (Conv2D) (None, 28, 28, 128) 32896 conv2_block3_out[0][0]
__________________________________________________________________________________________________
conv3_block1_1_bn (BatchNormali (None, 28, 28, 128) 512 conv3_block1_1_conv[0][0]
__________________________________________________________________________________________________
conv3_block1_1_relu (Activation (None, 28, 28, 128) 0 conv3_block1_1_bn[0][0]
__________________________________________________________________________________________________
conv3_block1_2_conv (Conv2D) (None, 28, 28, 128) 147584 conv3_block1_1_relu[0][0]
__________________________________________________________________________________________________
conv3_block1_2_bn (BatchNormali (None, 28, 28, 128) 512 conv3_block1_2_conv[0][0]
__________________________________________________________________________________________________
conv3_block1_2_relu (Activation (None, 28, 28, 128) 0 conv3_block1_2_bn[0][0]
__________________________________________________________________________________________________
conv3_block1_0_conv (Conv2D) (None, 28, 28, 512) 131584 conv2_block3_out[0][0]
__________________________________________________________________________________________________
conv3_block1_3_conv (Conv2D) (None, 28, 28, 512) 66048 conv3_block1_2_relu[0][0]
__________________________________________________________________________________________________
conv3_block1_0_bn (BatchNormali (None, 28, 28, 512) 2048 conv3_block1_0_conv[0][0]
__________________________________________________________________________________________________
conv3_block1_3_bn (BatchNormali (None, 28, 28, 512) 2048 conv3_block1_3_conv[0][0]
__________________________________________________________________________________________________
conv3_block1_add (Add) (None, 28, 28, 512) 0 conv3_block1_0_bn[0][0]
conv3_block1_3_bn[0][0]
__________________________________________________________________________________________________
conv3_block1_out (Activation) (None, 28, 28, 512) 0 conv3_block1_add[0][0]
__________________________________________________________________________________________________
conv3_block2_1_conv (Conv2D) (None, 28, 28, 128) 65664 conv3_block1_out[0][0]
__________________________________________________________________________________________________
conv3_block2_1_bn (BatchNormali (None, 28, 28, 128) 512 conv3_block2_1_conv[0][0]
__________________________________________________________________________________________________
conv3_block2_1_relu (Activation (None, 28, 28, 128) 0 conv3_block2_1_bn[0][0]
__________________________________________________________________________________________________
conv3_block2_2_conv (Conv2D) (None, 28, 28, 128) 147584 conv3_block2_1_relu[0][0]
__________________________________________________________________________________________________
conv3_block2_2_bn (BatchNormali (None, 28, 28, 128) 512 conv3_block2_2_conv[0][0]
__________________________________________________________________________________________________
conv3_block2_2_relu (Activation (None, 28, 28, 128) 0 conv3_block2_2_bn[0][0]
__________________________________________________________________________________________________
conv3_block2_3_conv (Conv2D) (None, 28, 28, 512) 66048 conv3_block2_2_relu[0][0]
__________________________________________________________________________________________________
conv3_block2_3_bn (BatchNormali (None, 28, 28, 512) 2048 conv3_block2_3_conv[0][0]
__________________________________________________________________________________________________
conv3_block2_add (Add) (None, 28, 28, 512) 0 conv3_block1_out[0][0]
conv3_block2_3_bn[0][0]
__________________________________________________________________________________________________
conv3_block2_out (Activation) (None, 28, 28, 512) 0 conv3_block2_add[0][0]
__________________________________________________________________________________________________
conv3_block3_1_conv (Conv2D) (None, 28, 28, 128) 65664 conv3_block2_out[0][0]
__________________________________________________________________________________________________
conv3_block3_1_bn (BatchNormali (None, 28, 28, 128) 512 conv3_block3_1_conv[0][0]
__________________________________________________________________________________________________
conv3_block3_1_relu (Activation (None, 28, 28, 128) 0 conv3_block3_1_bn[0][0]
__________________________________________________________________________________________________
conv3_block3_2_conv (Conv2D) (None, 28, 28, 128) 147584 conv3_block3_1_relu[0][0]
__________________________________________________________________________________________________
conv3_block3_2_bn (BatchNormali (None, 28, 28, 128) 512 conv3_block3_2_conv[0][0]
__________________________________________________________________________________________________
conv3_block3_2_relu (Activation (None, 28, 28, 128) 0 conv3_block3_2_bn[0][0]
__________________________________________________________________________________________________
conv3_block3_3_conv (Conv2D) (None, 28, 28, 512) 66048 conv3_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv3_block3_3_bn (BatchNormali (None, 28, 28, 512) 2048 conv3_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv3_block3_add (Add) (None, 28, 28, 512) 0 conv3_block2_out[0][0]
conv3_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv3_block3_out (Activation) (None, 28, 28, 512) 0 conv3_block3_add[0][0]
__________________________________________________________________________________________________
conv3_block4_1_conv (Conv2D) (None, 28, 28, 128) 65664 conv3_block3_out[0][0]
__________________________________________________________________________________________________
conv3_block4_1_bn (BatchNormali (None, 28, 28, 128) 512 conv3_block4_1_conv[0][0]
__________________________________________________________________________________________________
conv3_block4_1_relu (Activation (None, 28, 28, 128) 0 conv3_block4_1_bn[0][0]
__________________________________________________________________________________________________
conv3_block4_2_conv (Conv2D) (None, 28, 28, 128) 147584 conv3_block4_1_relu[0][0]
__________________________________________________________________________________________________
conv3_block4_2_bn (BatchNormali (None, 28, 28, 128) 512 conv3_block4_2_conv[0][0]
__________________________________________________________________________________________________
conv3_block4_2_relu (Activation (None, 28, 28, 128) 0 conv3_block4_2_bn[0][0]
__________________________________________________________________________________________________
conv3_block4_3_conv (Conv2D) (None, 28, 28, 512) 66048 conv3_block4_2_relu[0][0]
__________________________________________________________________________________________________
conv3_block4_3_bn (BatchNormali (None, 28, 28, 512) 2048 conv3_block4_3_conv[0][0]
__________________________________________________________________________________________________
conv3_block4_add (Add) (None, 28, 28, 512) 0 conv3_block3_out[0][0]
conv3_block4_3_bn[0][0]
__________________________________________________________________________________________________
conv3_block4_out (Activation) (None, 28, 28, 512) 0 conv3_block4_add[0][0]
__________________________________________________________________________________________________
conv4_block1_1_conv (Conv2D) (None, 14, 14, 256) 131328 conv3_block4_out[0][0]
__________________________________________________________________________________________________
conv4_block1_1_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block1_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block1_1_relu (Activation (None, 14, 14, 256) 0 conv4_block1_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block1_2_conv (Conv2D) (None, 14, 14, 256) 590080 conv4_block1_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block1_2_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block1_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block1_2_relu (Activation (None, 14, 14, 256) 0 conv4_block1_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block1_0_conv (Conv2D) (None, 14, 14, 1024) 525312 conv3_block4_out[0][0]
__________________________________________________________________________________________________
conv4_block1_3_conv (Conv2D) (None, 14, 14, 1024) 263168 conv4_block1_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block1_0_bn (BatchNormali (None, 14, 14, 1024) 4096 conv4_block1_0_conv[0][0]
__________________________________________________________________________________________________
conv4_block1_3_bn (BatchNormali (None, 14, 14, 1024) 4096 conv4_block1_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block1_add (Add) (None, 14, 14, 1024) 0 conv4_block1_0_bn[0][0]
conv4_block1_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block1_out (Activation) (None, 14, 14, 1024) 0 conv4_block1_add[0][0]
__________________________________________________________________________________________________
conv4_block2_1_conv (Conv2D) (None, 14, 14, 256) 262400 conv4_block1_out[0][0]
__________________________________________________________________________________________________
conv4_block2_1_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block2_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block2_1_relu (Activation (None, 14, 14, 256) 0 conv4_block2_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block2_2_conv (Conv2D) (None, 14, 14, 256) 590080 conv4_block2_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block2_2_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block2_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block2_2_relu (Activation (None, 14, 14, 256) 0 conv4_block2_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block2_3_conv (Conv2D) (None, 14, 14, 1024) 263168 conv4_block2_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block2_3_bn (BatchNormali (None, 14, 14, 1024) 4096 conv4_block2_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block2_add (Add) (None, 14, 14, 1024) 0 conv4_block1_out[0][0]
conv4_block2_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block2_out (Activation) (None, 14, 14, 1024) 0 conv4_block2_add[0][0]
__________________________________________________________________________________________________
conv4_block3_1_conv (Conv2D) (None, 14, 14, 256) 262400 conv4_block2_out[0][0]
__________________________________________________________________________________________________
conv4_block3_1_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block3_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block3_1_relu (Activation (None, 14, 14, 256) 0 conv4_block3_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block3_2_conv (Conv2D) (None, 14, 14, 256) 590080 conv4_block3_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block3_2_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block3_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block3_2_relu (Activation (None, 14, 14, 256) 0 conv4_block3_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block3_3_conv (Conv2D) (None, 14, 14, 1024) 263168 conv4_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block3_3_bn (BatchNormali (None, 14, 14, 1024) 4096 conv4_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block3_add (Add) (None, 14, 14, 1024) 0 conv4_block2_out[0][0]
conv4_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block3_out (Activation) (None, 14, 14, 1024) 0 conv4_block3_add[0][0]
__________________________________________________________________________________________________
conv4_block4_1_conv (Conv2D) (None, 14, 14, 256) 262400 conv4_block3_out[0][0]
__________________________________________________________________________________________________
conv4_block4_1_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block4_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block4_1_relu (Activation (None, 14, 14, 256) 0 conv4_block4_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block4_2_conv (Conv2D) (None, 14, 14, 256) 590080 conv4_block4_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block4_2_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block4_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block4_2_relu (Activation (None, 14, 14, 256) 0 conv4_block4_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block4_3_conv (Conv2D) (None, 14, 14, 1024) 263168 conv4_block4_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block4_3_bn (BatchNormali (None, 14, 14, 1024) 4096 conv4_block4_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block4_add (Add) (None, 14, 14, 1024) 0 conv4_block3_out[0][0]
conv4_block4_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block4_out (Activation) (None, 14, 14, 1024) 0 conv4_block4_add[0][0]
__________________________________________________________________________________________________
conv4_block5_1_conv (Conv2D) (None, 14, 14, 256) 262400 conv4_block4_out[0][0]
__________________________________________________________________________________________________
conv4_block5_1_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block5_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block5_1_relu (Activation (None, 14, 14, 256) 0 conv4_block5_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block5_2_conv (Conv2D) (None, 14, 14, 256) 590080 conv4_block5_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block5_2_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block5_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block5_2_relu (Activation (None, 14, 14, 256) 0 conv4_block5_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block5_3_conv (Conv2D) (None, 14, 14, 1024) 263168 conv4_block5_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block5_3_bn (BatchNormali (None, 14, 14, 1024) 4096 conv4_block5_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block5_add (Add) (None, 14, 14, 1024) 0 conv4_block4_out[0][0]
conv4_block5_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block5_out (Activation) (None, 14, 14, 1024) 0 conv4_block5_add[0][0]
__________________________________________________________________________________________________
conv4_block6_1_conv (Conv2D) (None, 14, 14, 256) 262400 conv4_block5_out[0][0]
__________________________________________________________________________________________________
conv4_block6_1_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block6_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block6_1_relu (Activation (None, 14, 14, 256) 0 conv4_block6_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block6_2_conv (Conv2D) (None, 14, 14, 256) 590080 conv4_block6_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block6_2_bn (BatchNormali (None, 14, 14, 256) 1024 conv4_block6_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block6_2_relu (Activation (None, 14, 14, 256) 0 conv4_block6_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block6_3_conv (Conv2D) (None, 14, 14, 1024) 263168 conv4_block6_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block6_3_bn (BatchNormali (None, 14, 14, 1024) 4096 conv4_block6_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block6_add (Add) (None, 14, 14, 1024) 0 conv4_block5_out[0][0]
conv4_block6_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block6_out (Activation) (None, 14, 14, 1024) 0 conv4_block6_add[0][0]
__________________________________________________________________________________________________
conv5_block1_1_conv (Conv2D) (None, 7, 7, 512) 524800 conv4_block6_out[0][0]
__________________________________________________________________________________________________
conv5_block1_1_bn (BatchNormali (None, 7, 7, 512) 2048 conv5_block1_1_conv[0][0]
__________________________________________________________________________________________________
conv5_block1_1_relu (Activation (None, 7, 7, 512) 0 conv5_block1_1_bn[0][0]
__________________________________________________________________________________________________
conv5_block1_2_conv (Conv2D) (None, 7, 7, 512) 2359808 conv5_block1_1_relu[0][0]
__________________________________________________________________________________________________
conv5_block1_2_bn (BatchNormali (None, 7, 7, 512) 2048 conv5_block1_2_conv[0][0]
__________________________________________________________________________________________________
conv5_block1_2_relu (Activation (None, 7, 7, 512) 0 conv5_block1_2_bn[0][0]
__________________________________________________________________________________________________
conv5_block1_0_conv (Conv2D) (None, 7, 7, 2048) 2099200 conv4_block6_out[0][0]
__________________________________________________________________________________________________
conv5_block1_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 conv5_block1_2_relu[0][0]
__________________________________________________________________________________________________
conv5_block1_0_bn (BatchNormali (None, 7, 7, 2048) 8192 conv5_block1_0_conv[0][0]
__________________________________________________________________________________________________
conv5_block1_3_bn (BatchNormali (None, 7, 7, 2048) 8192 conv5_block1_3_conv[0][0]
__________________________________________________________________________________________________
conv5_block1_add (Add) (None, 7, 7, 2048) 0 conv5_block1_0_bn[0][0]
conv5_block1_3_bn[0][0]
__________________________________________________________________________________________________
conv5_block1_out (Activation) (None, 7, 7, 2048) 0 conv5_block1_add[0][0]
__________________________________________________________________________________________________
conv5_block2_1_conv (Conv2D) (None, 7, 7, 512) 1049088 conv5_block1_out[0][0]
__________________________________________________________________________________________________
conv5_block2_1_bn (BatchNormali (None, 7, 7, 512) 2048 conv5_block2_1_conv[0][0]
__________________________________________________________________________________________________
conv5_block2_1_relu (Activation (None, 7, 7, 512) 0 conv5_block2_1_bn[0][0]
__________________________________________________________________________________________________
conv5_block2_2_conv (Conv2D) (None, 7, 7, 512) 2359808 conv5_block2_1_relu[0][0]
__________________________________________________________________________________________________
conv5_block2_2_bn (BatchNormali (None, 7, 7, 512) 2048 conv5_block2_2_conv[0][0]
__________________________________________________________________________________________________
conv5_block2_2_relu (Activation (None, 7, 7, 512) 0 conv5_block2_2_bn[0][0]
__________________________________________________________________________________________________
conv5_block2_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 conv5_block2_2_relu[0][0]
__________________________________________________________________________________________________
conv5_block2_3_bn (BatchNormali (None, 7, 7, 2048) 8192 conv5_block2_3_conv[0][0]
__________________________________________________________________________________________________
conv5_block2_add (Add) (None, 7, 7, 2048) 0 conv5_block1_out[0][0]
conv5_block2_3_bn[0][0]
__________________________________________________________________________________________________
conv5_block2_out (Activation) (None, 7, 7, 2048) 0 conv5_block2_add[0][0]
__________________________________________________________________________________________________
conv5_block3_1_conv (Conv2D) (None, 7, 7, 512) 1049088 conv5_block2_out[0][0]
__________________________________________________________________________________________________
conv5_block3_1_bn (BatchNormali (None, 7, 7, 512) 2048 conv5_block3_1_conv[0][0]
__________________________________________________________________________________________________
conv5_block3_1_relu (Activation (None, 7, 7, 512) 0 conv5_block3_1_bn[0][0]
__________________________________________________________________________________________________
conv5_block3_2_conv (Conv2D) (None, 7, 7, 512) 2359808 conv5_block3_1_relu[0][0]
__________________________________________________________________________________________________
conv5_block3_2_bn (BatchNormali (None, 7, 7, 512) 2048 conv5_block3_2_conv[0][0]
__________________________________________________________________________________________________
conv5_block3_2_relu (Activation (None, 7, 7, 512) 0 conv5_block3_2_bn[0][0]
__________________________________________________________________________________________________
conv5_block3_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 conv5_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv5_block3_3_bn (BatchNormali (None, 7, 7, 2048) 8192 conv5_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv5_block3_add (Add) (None, 7, 7, 2048) 0 conv5_block2_out[0][0]
conv5_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv5_block3_out (Activation) (None, 7, 7, 2048) 0 conv5_block3_add[0][0]
__________________________________________________________________________________________________
avg_pool (GlobalAveragePooling2 (None, 2048) 0 conv5_block3_out[0][0]
__________________________________________________________________________________________________
probs (Dense) (None, 1000) 2049000 avg_pool[0][0]
==================================================================================================
Total params: 25,636,712
Trainable params: 25,583,592
Non-trainable params: 53,120
__________________________________________________________________________________________________Vamos a ver que prediccion nos ofrece ResNet-50 para las siguientes imagenes

Las imagenes están albergadas en un array de 3 dimensiones(ancho, alto, canales de color)
from urllib.request import urlopen, Request
import matplotlib.pyplot as plt
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.3'}
imagen_perro = plt.imread(urlopen(Request('https://cdn.pixabay.com/photo/2015/11/17/13/13/dogue-de-bordeaux-1047521_1280.jpg', headers=headers)), format='jpg')
castillo = plt.imread(urlopen(Request('https://www.audioguiaroma.com/imagenes/castillo-san-angelo.jpg', headers=headers)), format='jpg')import tensorflow as tf
import numpy as np
imagen_perro_crop = tf.image.resize_with_pad(imagen_perro, 224, 224, antialias=True)
castillo_crop = tf.image.resize_with_pad(castillo, 224, 224, antialias=True)
imagenes = keras.applications.resnet50.preprocess_input(np.array([imagen_perro_crop, castillo_crop]))imagenes_test = imagenes_test.reshape(10000, 28, 28, 1);
imagenes_entrenamiento = imagenes_entrenamiento.reshape(60000, 28, 28, 1);pred = neural_network_on_steroids.predict(imagenes)top_K = keras.applications.resnet50.decode_predictions(pred, top=3)
for image_index in range(2):
print("Image #{}".format(image_index))
for class_id, name, y_proba in top_K[image_index]:
print(" {} - {:12s} {:.2f}%".format(class_id, name, y_proba * 100))
print() Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json
40960/35363 [==================================] - 0s 0us/step
Image #0
n02100583 - vizsla 58.95%
n02099712 - Labrador_retriever 29.05%
n02108422 - bull_mastiff 1.68%
Image #1
n03877845 - palace 45.57%
n03220513 - dome 23.81%
n02980441 - castle 12.66%
INSTALACIÓN DE TENSORFLOW
¿TensorFlow GPU o TensorFlow CPU? Si vas a instalar TensorFlow en tu ordenador tienes la posibilidad de escoger su versión GPU o CPU, si eres aún principiante sería recomendable instalar TensorFlow CPU, puedes aprender como hacerlo aquí
¿Qué es una CPU? es un procesador de tipo general, esto quiere decir que ejecuta todo tipo de comandos en una computadora, al no tener especifidad resulta menos eficiente realizando las operaciones matemáticas necesarias para desarrollar un modelo de Deep Learning.
¿Qué es una GPU? es un procesador de tipo específico, que se caracteriza por tener una gran cantidad de núcleos, lo cual facilita la ejecución de comandos en paralelo.
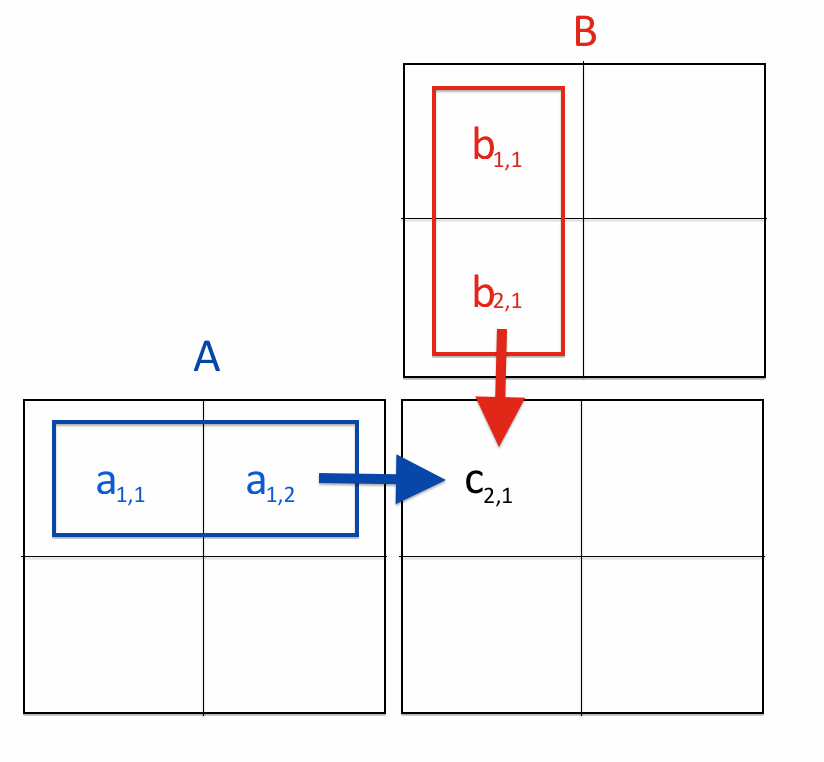
Como veis podemos paralelizar la multiplicación de una matriz, en lugar de calcular la matriz resultado elemento por elemento, podemos calcular de manera simúltanea los 4 elementos asignando un procesador a cada elemento. Esta es de manera general la idea detrás de usar GPU’s en Deep Learning
Si no quieres instalar TensorFlow en tu ordenador, puedes usar servicios como Google Colab o Kaggle, donde dispones de un limitado uso de GPU’s y CPU’s.
A hombros de gigante
Queremos dar las gracias a la vez que recomendar las siguientes fuentes que nos han servido de gran inspiración para elaborar este notebook:
- Andrew NG Standford Machine Learning
- Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow
- 3Blue1Brown Deep Learning(MUY RECOMENDABLE)
- MIT Introduction to Deep Learning
- Dot CSV Aprendiendo Inteligencia Artificial(ESPAÑOL)
{kind=link}